近日,数理医学院校聘教授楼威在Nature 旗下国际权威期刊npj Digital Medicine(五年影响因子17.0)发表题为“Key Concept Learning for Medical Vision Language Model with Reasoning Capabilities”的研究论文。浙江师范大学为论文第一完成单位,楼威教授为第一作者,香港理工大学眼科视光学院何明光教授与施丹莉教授为共同通讯作者,吴越为共同第一作者。

该研究聚焦医学视觉问答(VQA)这一人工智能辅助诊疗的核心任务。在眼科、放射科和病理科等临床场景中,精准诊断往往依赖于对影像中细微特征(如眼底微出血、玻璃膜疣或新生血管)的识别,并结合多步临床推理进行综合判断。然而,现有医疗视觉语言模型(VLMs)普遍存在“黑箱”问题:多数仅输出最终答案或基于预训练模式匹配生成的“伪解释”,缺乏对关键视觉证据的聚焦能力与可追溯的推理链条,导致模型透明度不足、临床信任度受限。此外,高性能医疗VLM的训练通常需要大规模、隐私合规的图文对齐数据,不仅成本高昂,也难以满足医院本地化、个性化部署的需求。
为应对上述挑战,该研究提出 ConceptVLM——一种数据高效,医学概念感知的多模态医学问答框架。研究团队整合了放射学、病理学及眼科学等多个高质量多模态数据集,构建了一个标准化的医学指令微调语料库,并在此基础上对通用视觉语言大模型进行高效直接微调。ConceptVLM 的核心创新在于引入“关键概念感知”机制,在注入领域专业知识的同时,有效保留模型原有的通用推理能力,显著缓解因小规模、低多样性数据微调所引发的灾难性遗忘问题。
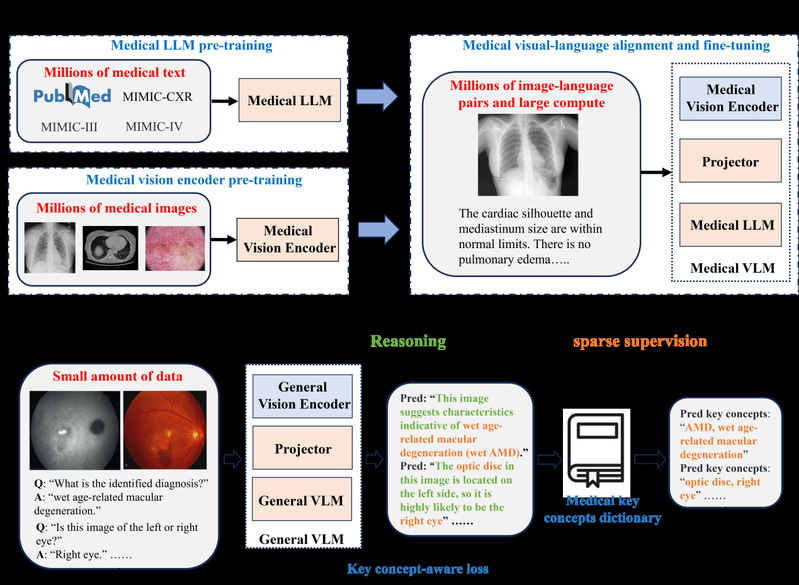
图1 ConceptVLM与现有VLM的设计范式对比图
该研究在涵盖眼科、放射学和病理学的七个医学VQA基准数据集及四个复杂临床推理测试集 上对 ConceptVLM 进行了系统评估。结果表明,该模型仅使用当前最先进方法 1% 的训练数据量,即可实现更高的回答准确率,并在处理多步骤临床问题方面表现显著优势。尤为突出的是,ConceptVLM 在未进行额外任务微调的情况下,展现出强大的多任务泛化能力,可稳健支持放射报告自动生成、鉴别诊断逻辑推演以及交互式患者咨询等多样化临床应用场景。
该研究证实,通过高质量小样本数据与概念驱动的微调策略,有希望在保障数据隐私与计算效率的前提下,构建具备类专家推理能力的医疗视觉语言模型,为基层医疗机构及科研单位开展低成本、可定制的AI临床辅助系统提供了可行路径。
